

前排提示:爬虫作为技术无关好坏,标题只是为了顺口
前置最好会一点python基本语法,遇到不懂的语法可查阅Python 基础教程
环境准备
一、安装python
安装步骤可参考python安装,其中pycharm只是一个让编程更方便的工具(IDE集成开发环境),推荐小白安装,只是对写爬虫来说太过臃肿。如果想用记事本写程序也不是不行
二、需要用到的库:
1.请求库(用于模拟向网页发送请求并获得返回的数据)
(1)urllib(自带库)
python自带的与网页请求相关的库
import urllib # 导入urllib库
python的爬虫只需要用urllib来发送请求,获得返回的响应,再进行解码转成可读的数据。这些实现步骤相较来说基础和复杂了点,故一般使用更为简洁明了的requests库来代替
(2)requests(常用库)
requests是python的一个第三方库,用来向网页发送请求,是对urllib库的再次封装,首先需要在命令行输入如下命令,用python的包管理器pip安装
pip install requests
在程序中调用也需要先导入,在python程序中导入requests库
import requests
(3)selenium
selenium是python的一个第三方库,用来操控浏览器打开网页并进行交互和获取网页数据,同样需要使用pip来安装并在代码中导入来调用
pip install selenium=3.4.1
只需要从selenium库中导入其中的Webdriver即可
from selenium import Webdriver
selenium一般是分析网页的反爬虫机制并无力破解的情况下用的不得已的措施,因为它需要打开浏览器来进行实际的请求,与其他方式通过模拟请求相比来得相对效率过低
selenium操控的浏览器只能是Chrome,如果要使用selenium,就要保证电脑上安装了Chrome浏览器,此外还要查看Chrome的版本,并下载对应的Chromedriver点击跳转下载页面
(4)Scrapy框架
Scrapy是python的爬虫框架,常用于企业级的爬虫开发,但学习成本和收益对个人爬虫来说性价比不高(如果对python已经比较熟悉就可以尝试学习),这里仅作介绍,
pip install Scrapy # 同样使用pip安装
scrapy # 同样通过在命令行界面输入scrapy来运行,出现以下提示就表示安装成功了

2.解析库(用于解析返回的数据并获得其中我们想要的部分)
(1)lxml
向网页发送请求返回源码后肯定不能手动从中把想要的那一部分截取下来,数据一多通过程序解析获取更为便捷,lxml库就是这样一个用于解析网页源码的库
从命令行安装
pip install lxml
在代码中导入库,需要使用其中的etree类
from lxml import etree
(2)BeautifulSoup4
和上面的lxml一样也是一个用来解析网页的库,区别在于它的解析方式更多样,但同样地使用难度也更高
pip install beautifulsoup4
bs4是beautifulsoup4库自己定义的简写,导入时要指定是bs4,需要使用其中的BeautifulSoup类
from bs4 import BeautifulSoup
(3)jsonpath
由于现在很多网页的数据并不直接写在网页的源码中(所谓前后端分离),尤其是ajax等网页加载方式的流行,使得现在的爬虫基本都需要解析json数据而不是网页源码,所以jsonpath作为一个解析json数据的库可以更加快速的从json数据中取得想要的那一部分
pip install jsonpath
import jsonpath
3.导出库(爬取到想要的数据后如果需要保存就需要写入本地或者上传到数据库)
(1)pandas
(2)pymysql
基本步骤(一个简单的例子)
一、请求获得网页源码
1.基础代码
import requests
url = "https://www.baidu.com"
# 以百度一下网页为目标,注意前面的地址前面是https而不是http
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76"
}
response = requests.get(url = url,headers = headers)
# 调用requests的get方法,并传入参数,再将返回的数据赋值给变量response
# 除了传入url,即网页的地址以外,还需要传入headers才能获得完整的网页源码,有兴趣可以看看加与不加headers返回的数据有什么不同
text = response.text
# 提取response的文本,其实就是获得网页源码的文本
print(text)
# 可以把网页源码的文本打印出来看是否获得了网页源码
2.如何获得headers?
headers在网页中翻译为标头,我们一般都需要标头里的User-Agent(简称UA)以此告知网页自己是个浏览器,才会给你返回完整的网页源码
在浏览器打开一个网页,按F12进入开发者模式

找到网络(Chrome浏览器里没有翻译,还是叫Network)
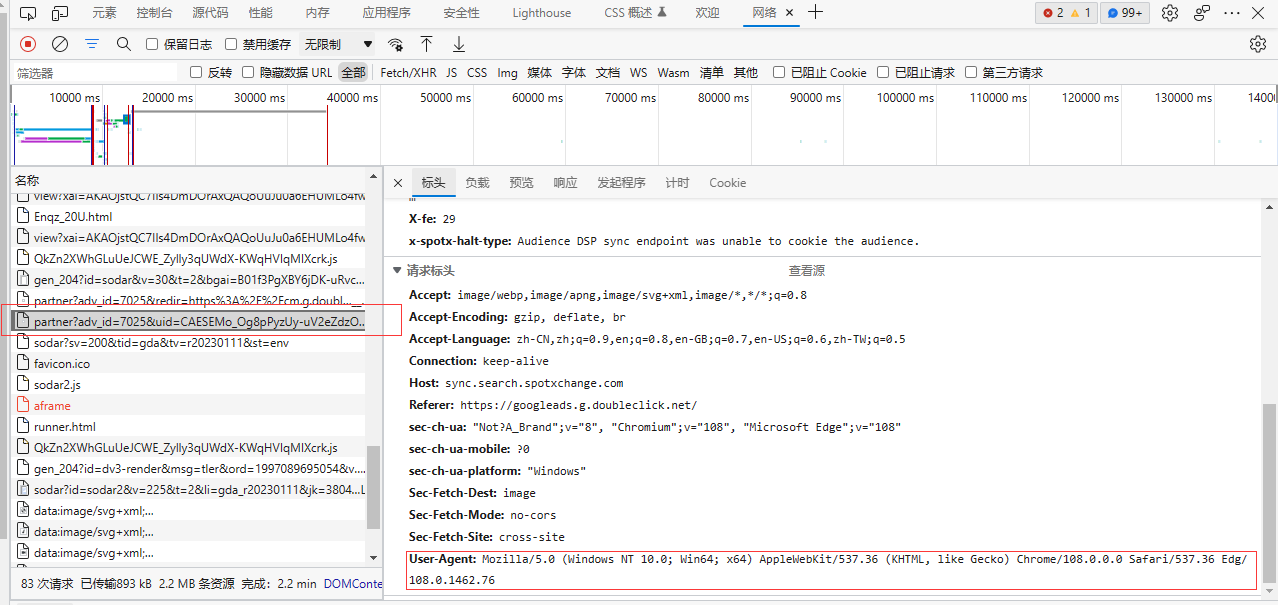
随便点一个请求(大部分请求都有),右边拉到最底下就能看到User-Agent,复制下来加到headers的大括号里,注意要把冒号前后的内容都加上引号
二、解析网页
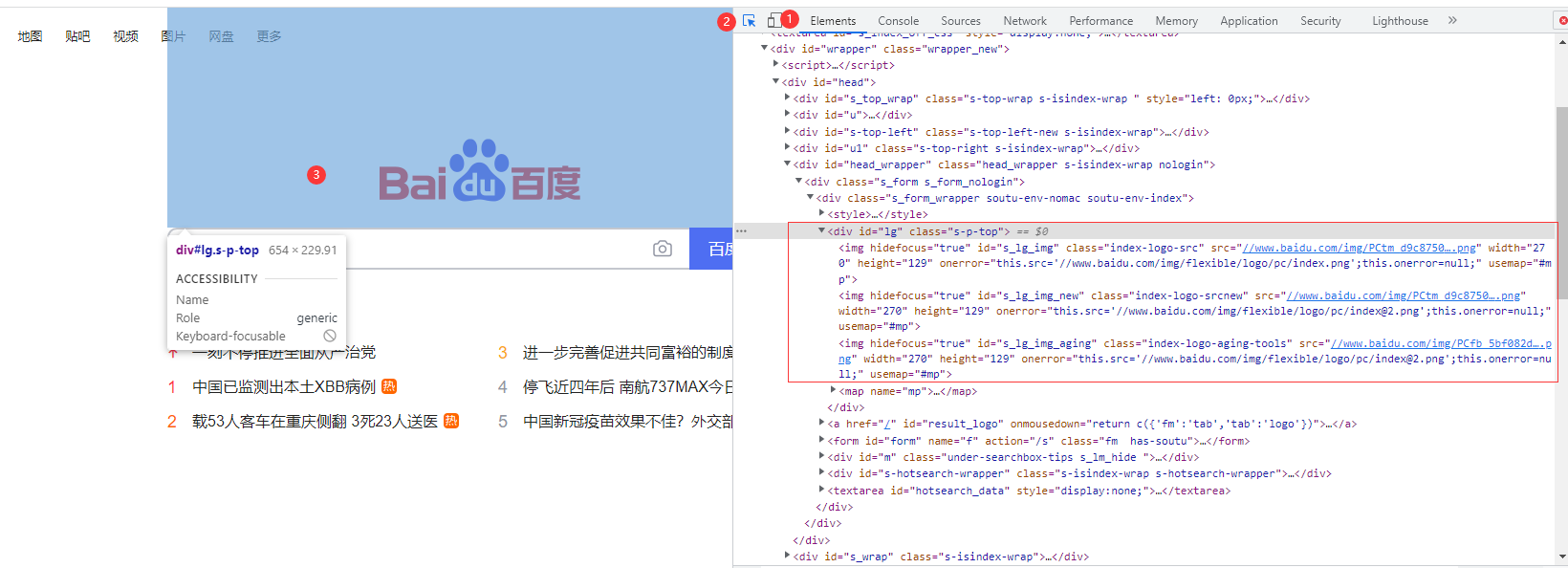
假设要获取百度一下首页的图片,那么同样进入开发者模式
点击第一个选项卡“元素”(Chrome浏览器同样没翻译叫Elements)
再点击“元素”往左第二个按钮,确保这个按钮被选中
最后把鼠标移到网页的这个图片上
点击之后就会发现右边的的网页源码界面直接跳转到了这个标签,展开后如图所示
1. 手动提取想要的数据
把这个标签里“src=”(src是source资源的缩写)后面的网址复制下来粘贴到浏览器的地址栏访问,会发现进入了一个只显示了这一张图片的网页,这其实就是这张图片在网络上的地址,也可以说是一个url链接,得到这个url链接就意味着可以把这张图片下载到自己的电脑上
2.爬虫提取想要的数据
在爬虫程序中程序化完成手动这个过程
首先还是要在网页的源码中定位,一般还是在开发者模式中直接定位
从上面的图片中可以大致图片链接所在位置周围的信息(这一步是解析网页的关键)
了解一下网页源码中的标签格式:<标签类型 属性名1=“属性值” 属性名2=”属性值“ ...... >标签的文本</标签类型>
(1)”src“作为属性所在的标签类型是“img”
(2)“img”的同级有三个也是“img”类型的标签
(3)这三个“img”标签的上级标签类型是“div”
(4)这个“div”标签有个“id”属性,值为“lg”,也可看到另一个属性“class”
可以在往上定位“div”的上级标签,一般定位到这一步足够了
# 接上面的代码,可以在print语句前加上#号把它注释掉
tree = etree.HTML(text)
# 调用etree的HTML方法,把网页源码的文本text传入其中,使之变成一个可以被解析的tree
img_srcs = tree.xpath('//div[@id = "lg"]/img/@src')
# 调用tree的xpath方法,也就是使用xpath的解析方式来解析网页,在括号里用字符串的形式传入解析的路径
# python里单引号和双引号都可以表示字符串类型,由于xpath路径中有双引号,所以外层必须使用单引号,才能保证不与内部的双引号混淆
# 开头的“//”表示:从网页源码的根目录开始查找所有的子标签和孙标签(也就是所有的标签)
# 'div[@id = "lg"]'表示:查找目标是一个div标签,中括号是匹配的条件——@属性名="属性值"
# 紧接着的“/”表示:查找已经找到的div标签下的子标签(不包括孙标签,也就是说指定了div的下一级,而不是div下面的所有层级)
# 'img'表示:找到div下一级的img标签
# '/@src'表示:img的下一级,src前加了“@”也就表示了需要的是img标签里的src属性的值
print(img_srcs)
# 打印出来查看结果

3.对数据进行处理
从结果中可以发现,得到的一个包含了三个字符串元素的列表(python中一种类似于数组的数据类型,用中括号来包围)
因为之前我们已经知道div标签下存在三个img标签,每个img标签里都有src属性,自然就会返回三个元素
此外,只要能找到元素,就算只有一个都会返回一个列表(否则返回一个布尔数据类型的false),所以还必须从列表中提取元素
提取列表的元素,只需要在列表后面加上一个中括号,里面填上要提取的元素的序号(从0开始计数),如:img_srcs[2]
如果仔细观察上面的结果还会发现,前面两个src链接是相同的,当然这不重要,这里先假设三张图片都是需要的
# 接上面的代码,同样地可以注释掉print
# 接下来要写一个简单的for循环来遍历列表,有以下两种方式
# 第一种方式:和上面的从列表中提取变量联系起来
# 下面的range(3)函数可暂时理解为一个列表(其实是可迭代对象),它的元素是[0,1,2],取不到3是因为range()前闭后开[0,3)
# range()函数里的参数也可以写成活代码,range(len(img_srcs)),通过len()函数获得列表的长度传入range()函数
for i in range(3):
img_src = img_srcs[i] # 第一次循环时 i为range(3)的第一个元素0,img_url = img_urls[0],以此类推
# 这里还有一个常见的问题需要处理——这里的src并非真正的url链接,它的开头没有http或https,不符合url链接的格式,之所以前面把它复制到浏览器地址栏可以跳转是因为浏览器自动补全了,所以需要通过字符串拼接让它成为一个真正的url链接
img_url = 'https:' + img_src
# 第二种方式:python的for循环很特殊,可以直接遍历列表(属于可迭代对象)的元素,这样写也更简洁优雅
#for img_src in img_srcs:
# print(img_src)
# 遍历列表里的每一个元素并打印出来
# img_url = 'https:' + img_src
# 拼接之后再赋值给真正的img_url
三、下载图片
遍历列表的获得列表的每一个元素,这里就是获得三张图片中每一张图片的url链接,接下来应该做什么?应该下载到电脑上
下载图片是同样需要使用requests库向图片所在的地址发送请求,问题在于返回的数据要获得什么类型,明显不能和上面一样获得文本类型
# 接上面的代码,注意这里缩进,缩进是python语法的重要部分绝对不能忽视
response = requests.get(url=img_url)
#图片所在的网页一般不需要传入headers了
content = response.content
# 与之前的response取text不同,这次取的content,返回的二进制数据,只有这样才能在后面用这些数据写为图片文件,同样的道理还可以之后写入视频文件
下一个问题是把二进制数据写到电脑上的一个文件里
path = str(i+1)+'.jpg'
# 借用for循环里的i用作图片文件的命名,把整数int类型强制转换为string字符串类型拼接后面的文件拓展名,就得到一个完整的文件名
# 这里其实是文件的路径,所以在文件名前面可以加上如'F:/'这样的路径来指定文件存放的位置
# 还要注意大多编程语言把'\'作为转义符号,为了避免混淆可以把路径中的'\\'和'\'全都用'/'代替
fp = open(path,'wb')
# 第二个参数'wb'中的'w'表示写入文件,'b'表示以二进制的方式,合起来是以二进制方式写入文件,打开的这个文件对象指定给了变量fp
fp.write(content)
# 写入语句,content就是上面访问图片地址返回的二进制数据
fp.close()
# 最后一定要注意关闭这个文件
运行,就会发现程序文件所在的目录多出了1.jpg,2.jpg,3.jpg三张图片
四、总结
这只是爬虫的一个简单案例,但包含了爬虫的几个步骤:
第一步,获取网页返回的数据
第二步,解析数据从中提取需要的部分
第三步,把提取到的数据转移到更方便取用的地方如本地的文件、数据库或者云端的数据等
其中最耗费时间的是第二步
常见爬虫案例与讲解(重点)
一、UA反爬
上面的基础案例就是UA反爬,网站会检查请求来自于什么浏览器,这就需要在标头headers中传入User-Agent参数来表明来源
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.76"
}
response = requests.get(url = url, headers = headers)
二、资源懒加载
为了节省用户访问网站的加载时间,网站加载一些占用较大的资源时会使用懒加载策略,就是用户在浏览器上的操作来判断是否加载需要的资源,是用JavaScript编写的浏览器脚本实现的,为了保存和调用方便,一般会把资源的链接或内容放在非常容易找到的地方,比如下面这个img标签就是一个非常经典的图片懒加载案例
